
深度学习
ICT-AI
谨以此文记录我在华为ICT大赛的学习过程
一些碎碎念
根据我的经验,应该有一个人学习环境搭建,这块很好上手。注册一个华为云账号多创建几次项目就可以了
理想中的最佳配队伍应该是一个人去做环境的部分包括云和开发版,快速把环境准备好,一个人去做主力,代码补全能尽力去把项目跑通,还有个则可以去学习性能调优。但是我估计这个配队应该够呛能凑出来。
哦对了关于开发版,那玩应性能很烂Jupyter多开直接就能给你卡死,建议前期案例跑通之后直接把代码放到ModelArts上跑(虽然很贵,但是肯定不会让你掏钱的)
附加一个开发版风扇转速命令
npu-smi set -t pwm-mode -d value
# value 0为手动模式 1为自动模式
npu-smi set -t pwm-duty-ratio -d value
# value 直接调100就可以了,虽然吵了一点但比过热死机强。
我还是推荐去学习Pythoch的,毕竟是现在主流的学习框架,只要学明白了同类型的代码基本就能看懂了。
Pytorch
- 数据:包括数据读取,数据清洗,进行数据划分和数据预处理,比如读取图片如何预处理及数据增强。
- 模型:包括构建模型模块,组织复杂网络,初始化网络参数,定义网络层。
- 损失函数:包括创建损失函数,设置损失函数超参数,根据不同任务选择合适的损失函数。
- 优化器:包括根据梯度使用某种优化器更新参数,管理模型参数,管理多个参数组实现不同学习率,调整学习率。
- 迭代训练:组织上面 4 个模块进行反复训练。包括观察训练效果,绘制 Loss/ Accuracy 曲线,用 TensorBoard 进行可视化分析。
CNN卷积神经网络算法原理
全连接神经网络
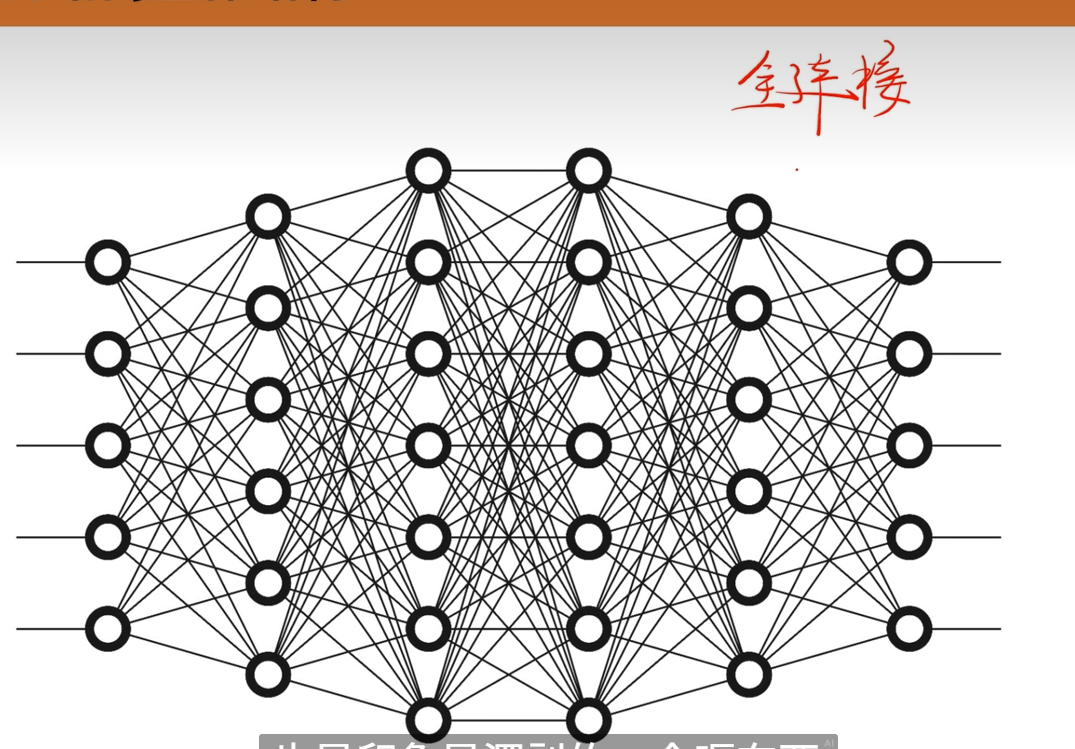
输入层 隐藏层 输出层
这里接着你的笔记,补上JupyterLab Notebook + 开源小项目的实战篇。我会假设你已经有华为云账号,并且会连带提一下怎么在开发板/ModelArts 上跑起来。
JupyterLab Notebook + 开源小项目实战
为什么要用 JupyterLab
JupyterLab 你可以理解为“网页版 VS Code + 交互式 Python 控制台”。特别适合学习阶段:
- 可以逐个单元格运行代码,立刻看到结果
- 配合 Markdown 写笔记,所有内容都在一个
.ipynb文件里 - 支持图片、可视化图表直接内嵌展示
- 能分屏同时看代码、终端、变量、帮助文档
在 ICT 学习过程中,我强烈建议所有实验都先在 JupyterLab 里跑通,确认代码逻辑没问题后,再搬到生产脚本或 ModelArts 任务里。
1. 环境选择建议(避坑指南)
前面提到开发板性能烂,Jupyter 多开会卡死。所以得分场景来:
| 场景 | 方案 | 注意点 |
|---|---|---|
| 边学边调试(小模型) | 开发板上跑 JupyterLab,只打开一个 Notebook | 风扇开满,做好散热 |
| 需要流畅体验 / 装很多包 | 华为云 ModelArts 的 Notebook 实例 | 按需付费也便宜 |
| 跑开源项目完整训练 | ModelArts 训练作业 / 直接本地用 PyCharm 脚本 | 不建议在 Jupyter 里跑几个小时的训练,容易断开 |
推荐做法:
- 前期学习,直接在开发板上
jupyter lab --ip=0.0.0.0 --port=8888启动,用电脑浏览器连过去。 - 代码逻辑验证完,把整个
.ipynb下载下来,或者导出.py,上传到 ModelArts Notebook 里用 GPU 实例跑。
2. 如何用 JupyterLab 搭配开源项目学习
核心思路:找一个干净的小项目 → 把它拆成可运行的小块 → 在 Notebook 里一行一行地执行、修改、观察。
选项目原则
- 结构不要太复杂,单一任务(比如 MNIST 手写数字分类)
- 代码量几百行以内
- 官方 example 或经典的 pytorch-tutorial 仓库
下面拿 PyTorch 官方 examples 里的 MNIST CNN 做例子,我把它改造成适合 Notebook 交互学习的版本。
3. 实战:在 Notebook 里拆解一个 CNN 项目
准备工作
# 在开发板或 ModelArts 终端里
git clone https://github.com/pytorch/examples.git
cd examples/mnist
# 安装依赖(如果你环境里没有)
pip install torchvision matplotlib tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple
启动 JupyterLab,新建一个 Notebook。
Step 1:导入包、检查设备
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
如果是开发板(昇腾),这里可以换成 torch_npu,但用 PyTorch 官方例子我们先用 CPU 验证。
Step 2:数据加载 + 可视化几张图
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
# 可视化几个样本
examples = iter(train_loader)
samples, labels = next(examples)
plt.figure(figsize=(10, 4))
for i in range(6):
plt.subplot(2, 3, i+1)
plt.imshow(samples[i][0], cmap='gray')
plt.title(f"Label: {labels[i]}")
plt.axis('off')
plt.show()
运行完你就能直接看到 MNIST 的手写数字长啥样,直观。
Step 3:定义网络(CNN)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
model = Net().to(device)
print(model)
你可以在这个单元格里随意修改层数、kernel_size,再执行一次看看参数量变化,这就是 Notebook 的优势。
Step 4:训练 + 验证循环(带可视化)
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.NLLLoss()
epochs = 3
train_losses = []
for epoch in range(epochs):
model.train()
running_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(train_loader)
train_losses.append(avg_loss)
# 验证
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1)
correct += pred.eq(target).sum().item()
acc = 100. * correct / len(test_dataset)
print(f'Epoch {epoch+1}: Loss={avg_loss:.4f}, Test Acc={acc:.2f}%')
# 画 Loss 曲线
plt.plot(range(1, epochs+1), train_losses, marker='o')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.grid()
plt.show()
跑完你可以立刻看到 loss 下降曲线和准确率,方便调参。
Step 5:看模型预测错了哪些图(Debug 神器)
model.eval()
test_iter = iter(test_loader)
data, target = next(test_iter)
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1)
# 找出前 6 个预测错的样本
wrong_idx = (pred != target).nonzero(as_tuple=True)[0][:6]
plt.figure(figsize=(12, 8))
for i, idx in enumerate(wrong_idx):
plt.subplot(2, 3, i+1)
plt.imshow(data[idx].cpu().squeeze(), cmap='gray')
plt.title(f'True: {target[idx]}, Pred: {pred[idx]}')
plt.axis('off')
plt.show()
这对理解模型弱点非常有用。
4. 如何用开源小项目拓展学习
等你把 MNIST 这个例子吃透,就可以去 GitHub 上搜一些小而美的 PyTorch 项目,用同样的方式拆解。推荐几个:
- pytorch-cifar:训练 ResNet 在 CIFAR-10 上,代码几百行
- pytorch-classification:包含多种经典网络实现
- timm(pytorch-image-models):库很大,但你可以只取一个模型文件,搭配自己的训练循环来学
打开项目后:
- 把
main.py或train.py里的代码按功能拆成不同单元格 - 每个单元格加上 Markdown 说明这个部分在做什么
- 修改某些参数,看结果变化,记录在笔记里
5. 关于 ModelArts Notebook 的特别说明
如果你觉得开发板实在卡,可以这么干:
- 进入华为云 ModelArts 控制台 → 开发环境 → Notebook
- 创建一个 GPU 实例(按需付费,用完立即停止)
- 启动 JupyterLab,上传你的
.ipynb和数据集 - 代码不需要大改,只需要注意
device = torch.device('cuda')即可 - 训练时打开 TensorBoard:
%load_ext tensorboard,然后%tensorboard --logdir runs,直接在 Notebook 里看曲线
省钱的技巧:训练任务跑完了,立即把 Notebook 实例停止(不是删除),数据会保存,下次重新启动再接着写笔记。
6. 把你的笔记和开源项目融会贯通
最后建议你把这篇笔记和之前的 CNN 原理结合起来,在 JupyterLab 里完成一次完整的“从原理到代码”的闭环:
- 上面 Cell:写 Markdown 描述卷积层是如何提取边缘特征的
- 下面 Cell:定义一个简单的边缘检测卷积核(如
[[-1,-1,-1],[0,0,0],[1,1,1]]),对输入图片做F.conv2d并可视化特征图
这样你的笔记本就既是原理手册,又是可运行的验证工具。ICT 比赛时,你甚至可以把这个整理成文档直接提交或答辩演示。
下一步:我会在下一篇笔记里写怎么引入 TensorBoard 做精细化可视化,以及如何在 ModelArts 上跑完整的训练作业。